Following Matrix Multiplication, we accelerate matrix multiplication on a CUDA GPU using tf::cudaGraph. The GPU's massive thread-level parallelism reduces large problem runtimes from minutes to milliseconds.
CUDA Kernel
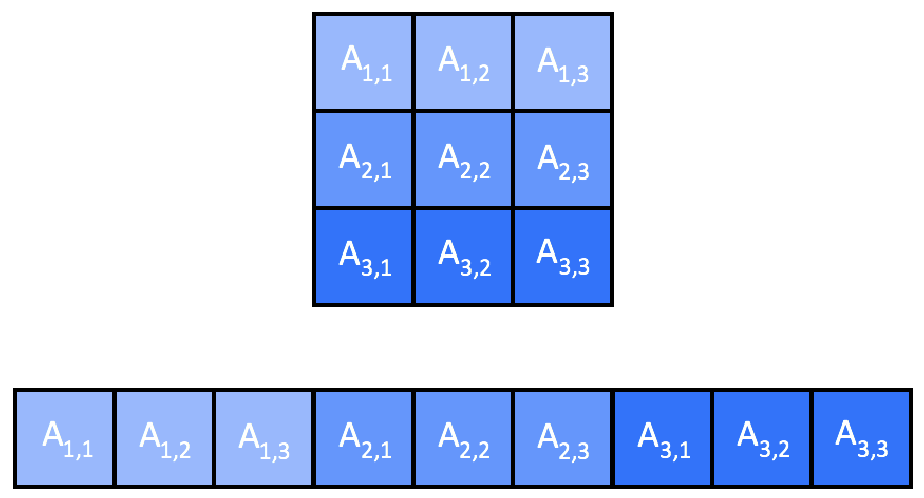
Unlike the CPU version where each task processes one row, on the GPU we assign one CUDA thread to each element of C. We store all matrices in 1D row-major layout to simplify host-to-device transfers: element (x, y) in a matrix of width W is stored at index x * W + y.
The CUDA kernel is:
__global__ void matmul(int* A, int* B, int* C, int M, int K, int N) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
int sum = 0;
if(row < M && col < N) {
for(int i = 0; i < K; i++) {
sum += A[row * K + i] * B[i * N + col];
}
C[row * N + col] = sum;
}
}
Each thread computes one element of C by iterating over the full inner dimension K.
CUDA Graph Task
We build a Taskflow that allocates GPU memory in parallel, runs the CUDA graph, and frees GPU memory when done:
void matrix_multiplication(int* A, int* B, int* C, int M, int K, int N) {
int *da, *db, *dc;
cudaMalloc(&da, M * K * sizeof(int));
}).name("allocate_a");
cudaMalloc(&db, K * N * sizeof(int));
}).name("allocate_b");
cudaMalloc(&dc, M * N * sizeof(int));
}).name("allocate_c");
tf::Task cuda = taskflow.
emplace([&]() {
tf::cudaTask copy_da = cg.
copy(da, A, M * K);
tf::cudaTask copy_db = cg.
copy(db, B, K * N);
dim3 grid ((N + 15) / 16, (M + 15) / 16);
dim3 block(16, 16);
tf::cudaTask kmatmul = cg.
kernel(grid, block, 0,
matmul, da, db, dc, M, K, N
);
tf::cudaTask copy_hc = cg.
copy(C, dc, M * N);
}).name("cuda");
tf::Task free_mem = taskflow.
emplace([&]() {
cudaFree(da);
cudaFree(db);
cudaFree(dc);
}).name("free");
cuda.
succeed(allocate_a, allocate_b, allocate_c)
executor.
run(taskflow).wait();
}
class to create an executor
Definition executor.hpp:62
tf::Future< void > run(Taskflow &taskflow)
runs a taskflow once
Task emplace(C &&callable)
creates a static task
Definition flow_builder.hpp:1738
class to create a task handle over a taskflow node
Definition task.hpp:569
Task & succeed(Ts &&... tasks)
adds precedence links from other tasks to this
Definition task.hpp:1313
Task & precede(Ts &&... tasks)
adds precedence links from this to other tasks
Definition task.hpp:1305
class to create a taskflow object
Definition taskflow.hpp:64
cudaTask copy(T *tgt, const T *src, size_t num)
creates a memcopy task that copies typed data
Definition cuda_graph.hpp:1075
cudaTask kernel(dim3 g, dim3 b, size_t s, F f, ArgsT... args)
creates a kernel task
Definition cuda_graph.hpp:1010
cudaStreamBase & synchronize()
synchronizes the associated stream
Definition cuda_stream.hpp:232
cudaStreamBase & run(const cudaGraphExecBase< C, D > &exec)
runs the given executable CUDA graph
cudaTask & succeed(Ts &&... tasks)
adds precedence links from other tasks to this
Definition cuda_graph.hpp:418
cudaTask & precede(Ts &&... tasks)
adds precedence links from this to other tasks
Definition cuda_graph.hpp:407
cudaGraphExecBase< cudaGraphExecCreator, cudaGraphExecDeleter > cudaGraphExec
default smart pointer type to manage a cudaGraphExec_t object with unique ownership
Definition cudaflow.hpp:23
cudaGraphBase< cudaGraphCreator, cudaGraphDeleter > cudaGraph
default smart pointer type to manage a cudaGraph_t object with unique ownership
Definition cudaflow.hpp:18
cudaStreamBase< cudaStreamCreator, cudaStreamDeleter > cudaStream
default smart pointer type to manage a cudaStream_t object with unique ownership
Definition cuda_stream.hpp:340
The outer Taskflow manages CPU-side orchestration: the three allocation tasks run in parallel, then the CUDA graph task runs, and finally GPU memory is freed. Inside the CUDA graph, two H2D copy tasks feed the kernel and the kernel feeds the D2H copy task. The CPU taskflow graph is shown below:
After execution, the full task graph including the CUDA sub-graph can be visualised:
Benchmarking
We compare three versions — sequential CPU, parallel CPU, and one GPU — on a 12-core Intel i7-8700 at 3.20 GHz and a Nvidia RTX 2080:
| Matrix size | CPU sequential | CPU parallel | GPU |
| 10×10 | 0.142 ms | 0.414 ms | 82 ms |
| 100×100 | 1.641 ms | 0.733 ms | 83 ms |
| 1000×1000 | 1532 ms | 504 ms | 85 ms |
| 2000×2000 | 25688 ms | 4387 ms | 133 ms |
| 3000×3000 | 104838 ms | 16170 ms | 214 ms |
| 4000×4000 | 250133 ms | 39646 ms | 427 ms |
For small matrices the GPU's data transfer overhead dominates and CPU solutions are faster. As problem size grows, the GPU's thread-level parallelism dominates completely. At 4000×4000, the GPU is 585× faster than the sequential CPU and 92× faster than the parallel CPU solution.