Task-parallel Pipeline with Token Dependencies
Taskflow pipeline allows you to defer the execution of a token to future tokens. This deferral introduces a dependency from a future token to the current token, particularly suitable for many video encoding applications. We recommend reading Task-parallel Pipeline first before learning this interface.
Understand Token Dependencies
Token dependencies establish the order in which data tokens should execute in a task-parallel pipeline. When token t1 completes before t2 starts, there is a dependency from t1 to t2. We categorize token dependencies into two types:
- forward token dependencies (FTD): dependencies from earlier to future tokens
- backward token dependencies (BTD): dependencies from future to earlier tokens The following figure illustrates a sample token dependency diagram and its token execution sequence. Edge pointing from token 2 to 5 is FTD, and those from 8 to 2 and 5 and 9 to 5 are BTDs. Based on the dependencies, the tokens execute in the corresponding execution sequence.

Resolve Token Dependencies
To resolve the token dependencies, the basic idea is to defer the execution of a token with unresolved dependencies and save the token in a data structure until its dependencies are resolved. To implement the idea, we leverage three data structures, deferred_tokens (DT), token_dependencies (TD), and ready_tokens (RT). DT and TD are associative containers and RT is a queue. DT stores deferred tokens and their dependents by which the deferred tokens are deferred. TD stores a dependent and its related deferred tokens. RT stores the tokens that were deferred tokens and now are ready because their dependencies are resolved. The following image illustrates the usages of the three data structures to resolve the token dependencies and get the corresponding serial execution sequence exemplified in Understand Token Dependencies.
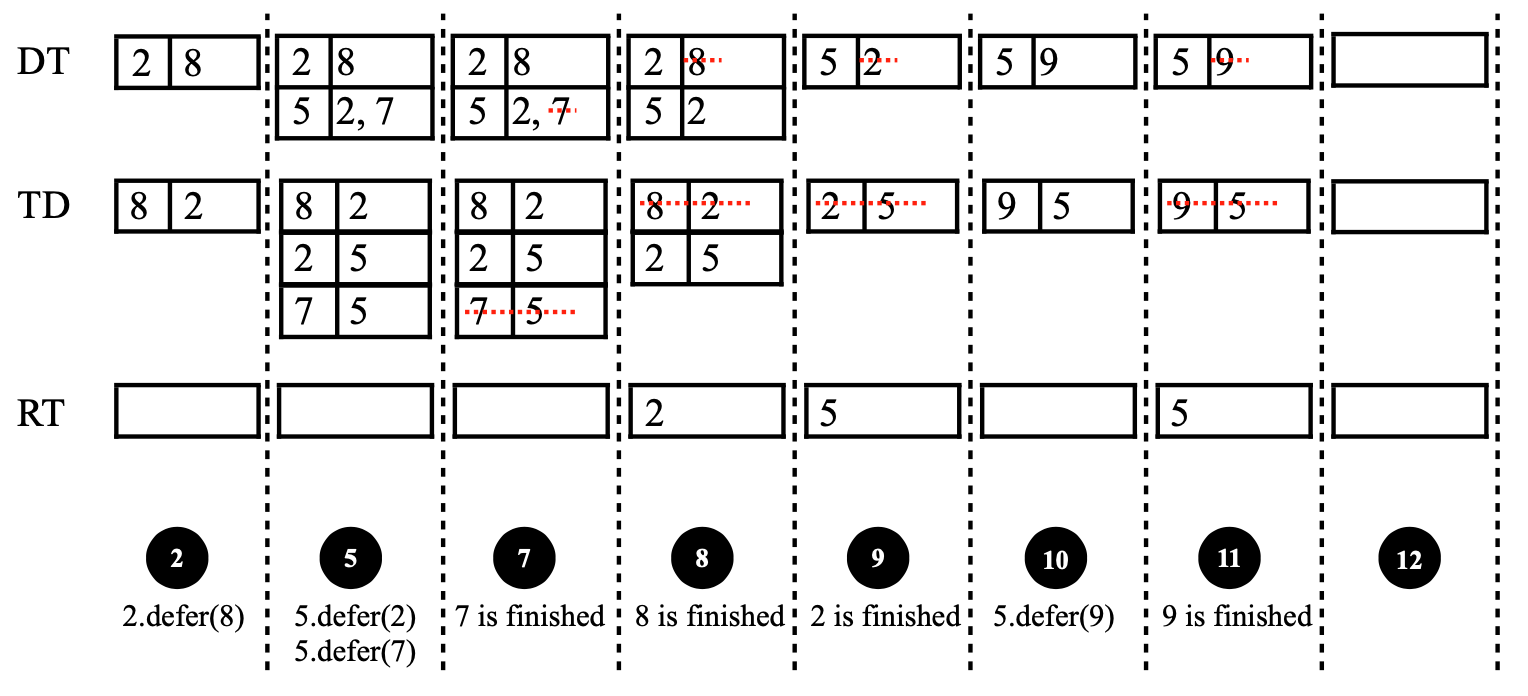
The whole process has the following steps:
- Token 1 is not a deferred token and then 1 is finished. Now the execution sequence is {1}.
- Token 2 defers to 8. We insert DT[2]={8} and TD[8]={2}. The black circle 2 in the above image illustrates this step.
- Token 3 is not a deferred token and then 3 is finished. Now the execution sequence is {1,3}.
- Token 4 is not a deferred token and then 4 is finished. Now the execution sequence is {1,3,4}.
- Token 5 defers to 2 and 7. We insert DT[5]={2,7}, TD[2]={5}, and TD[7]={5}. The black circle 5 in the above image illustrates this step.
- Token 6 is not a deferred token and then 6 is finished. Now the execution sequence is {1,3,4,6}.
- Token 7 is not a deferred token and then 7 is finished. Now the execution sequence is {1,3,4,6,7}. Since TD[7]={5}, we directly remove 7 from DT[5]. The black circle 7 in the above image illustrates this step.
- Token 8 is not a deferred token and then 8 is finished. Now the execution sequence is {1,3,4,6,7,8}. Since TD[8]={2}, we directly remove 8 from DT[2] and find out DT[2] is empty. Now token 2 is no longer a deferred token and we move 2 to RT. The black circle 8 in the above image illustrates this step.
- RT is not empty and has a token 2. Then we finish running 2. Now the execution sequence is {1,3,4,6,7,8,2}. Since TD[2]={5}, we directly remove 2 from DT[5] and find out DT[5] is empty. Now token 5 is no longer a deferred token and we move 5 to RT. The black circle 9 in the above image illustrates this step.
- RT is not empty and has a token 5. Then we run 5 and find out token 5 defers the second time, defers to 9. We insert DT[5]={9} and TD[9]={5}. The black circle 20 in the above image illustrates this step.
- Token 9 is not a deferred token and then 9 is finished. Now the execution sequence is {1,3,4,6,7,8,2,9}. Since TD[9]={5}, we directly remove 9 from DT[5] and find out DT[5] is empty. Now token 5 is no longer a deferred token and we move 5 to RT. The black circle 11 in the above image illustrates this step.
- RT is not empty and has a token 5. Then we finish running 5. Now the execution sequence is {1,3,4,6,7,8,2,9,5}. The black circle 12 in the above image illustrates this step.
- Token 10 is not a deferred token and then 10 is finished. Now the execution sequence is {1,3,4,6,7,8,2,9,5,10}.
Include the Header
You need to include the header file, taskflow/algorithm/pipeline.hpp, for implementing deferred pipeline algorithms.
#include <taskflow/algorithm/pipeline.hpp>
Create a Deferred Pipeline Module Task
To create a deferred pipeline application, there are four steps, one more step than creating a task-parallel pipeline (tf::
- Define the pipeline structure (e.g., pipe type, pipe callable, stopping rule, line count)
- Define the token dependencies at the first pipe
- Define the data storage and layout, if needed for the application
- Define the pipeline taskflow graph using composition
The following example demonstrates the creation of a deferred pipeline application exemplified in the dependency diagram in Understand Token Dependencies. The example creates a deferred pipeline that generates a total of 10 data tokens. The pipeline structure consists of four lines and three stages (all serial types).
1: tf::Taskflow taskflow("deferred_pipeline"); 2: tf::Executor executor; 3: 4: const size_t num_lines = 4; 5: 6: // the pipeline consists of three pipes (serial-serial-serial) 7: // and up to four concurrent scheduling tokens 8: tf::Pipeline pl(num_lines, 9: tf::Pipe{tf::PipeType::SERIAL, [](tf::Pipeflow& pf) { 10: // stop at 11 scheduling tokens 11: if(pf.token() == 11) { 12: pf.stop(); 13: } 14: else { 15: // Token 5 is deferred 16: if (pf.token() == 5) { 17: switch(pf.num_deferrals()) { 18: case 0: 19: pf.defer(2); 20: printf("1st-time: Token %zu is deferred by 2\n", pf.token()); 21: pf.defer(7); 22: printf("1st-time: Token %zu is deferred by 7\n", pf.token()); 23: return; 24: break; 25: 26: case 1: 27: pf.defer(9); 28: printf("2nd-time: Token %zu is deferred by 9\n", pf.token()); 29: return; 30: break; 31: 32: case 2: 33: printf("3rd-time: Tokens 2, 7 and 9 resolved dependencies \ for token %zu\n", pf.token()); 34: break; 35: } 36: } 37: // token 2 is deferred 38: else if (pf.token() == 2) { 39: switch(pf.num_deferrals()) { 40: case 0: 41: pf.defer(8); 42: printf("1st-time: Token %zu is deferred by 8\n", pf.token()); 43: break; 44: case 1: 45: printf("2nd-time: Token 8 resolved dependencies for token %zu\n", pf.token()); 46: break; 47: } 48: } 49: else { 50: printf("stage 1: Non-deferred token %zu\n", pf.token()); 51: } 52: } 53: }}, 54: 55: tf::Pipe{tf::PipeType::SERIAL, [](tf::Pipeflow& pf) { 56: printf("stage 2: input token %zu (deferrals=%zu)\n", pf.token(), pf.num_deferrals()); 57: }}, 58: 59: tf::Pipe{tf::PipeType::SERIAL, [](tf::Pipeflow& pf) { 60: printf("stage 3: input token %zu\n", pf.token()); 61: }} 62: ); 63: 64: tf::Task task = taskflow.composed_of(pl); 65: 66: // run the pipeline 67: executor.run(taskflow).wait();
Debrief:
- Line 8 defines the number of lines in the pipeline
- Lines 9-52 define the first serial pipe, which will stop the pipeline scheduling at the 11th token
- Lines 15-30 define the token dependencies for token 5
- Lines 37-48 define the token dependencies for token 2
- Lines 55-57 define the second serial pipe
- Lines 59-61 define the third serial pipe
- Line 64 defines the pipeline taskflow graph using composition
- Line 67 executes the taskflow
The following is one of the possible outcomes of the example.
stage 1: Non-deferred token 0 stage 2: input token 0 (deferrals=0) stage 3: input token 0 stage 1: Non-deferred token 1 stage 2: input token 1 (deferrals=0) stage 3: input token 1 1st-time: Token 2 is deferred by 8 stage 1: Non-deferred token 3 stage 2: input token 3 (deferrals=0) stage 3: input token 3 stage 1: Non-deferred token 4 stage 2: input token 4 (deferrals=0) stage 3: input token 4 1st-time: Token 5 is deferred by 2 1st-time: Token 5 is deferred by 7 stage 1: Non-deferred token 6 stage 2: input token 6 (deferrals=0) stage 1: Non-deferred token 7 stage 2: input token 7 (deferrals=0) stage 1: Non-deferred token 8 stage 3: input token 6 stage 3: input token 7 stage 2: input token 8 (deferrals=0) stage 3: input token 8 2nd-time: Token 8 resolved dependencies for token 2 stage 2: input token 2 (deferrals=1) stage 3: input token 2 2nd-time: Token 5 is deferred by 9 stage 1: Non-deferred token 9 stage 2: input token 9 (deferrals=0) stage 3: input token 9 3rd-time: Tokens 2, 7 and 9 resolved dependencies for token 5 stage 2: input token 5 (deferrals=2) stage 3: input token 5 stage 1: Non-deferred token 10 stage 2: input token 10 (deferrals=0) stage 3: input token 10
Create a Deferred Scalable Pipeline Module Task
In addition to task-parallel pipeline (tf::
To create a deferred scalable pipeline application, there are four steps, which are identical to the steps described in Create a Deferred Pipeline Module Task. They are:
- Define the pipeline structure (e.g., pipe type, pipe callable, stopping rule, line count)
- Define the token dependencies at the first pipe
- Define the data storage and layout, if needed for the application
- Define the pipeline taskflow graph using composition
The following code creates a deferred scalable pipeline that uses four parallel lines to schedule tokens through two serial pipes in the given vector, then resetting that pipeline to three serial pipes. The three pipe callables are identical to the pipe callables demonstrated in the code snippet in Create a Deferred Pipeline Module Task. The token dependencies are exemplified in Understand Token Dependencies.
1: // create a vector of three pipes 2: std::vector< tf::Pipe<std::function<void(tf::Pipeflow&)>> > pipes; 3: 4: // define pipe callables 5: // first_pipe_callable is same as lines 15-53 in the above code snippet 6: auto first_pipe_callable = [](tf::Pipeflow& pf) { 7: // stop at 11 scheduling tokens 8: if(pf.token() == 11) { 9: pf.stop(); 10: } 11: else { 12: // Token 5 is deferred 13: if (pf.token() == 5) { 14: switch(pf.num_deferrals()) { 15: case 0: 16: pf.defer(2); 17: printf("1st-time: Token %zu is deferred by 2\n", pf.token()); 18: pf.defer(7); 19: printf("1st-time: Token %zu is deferred by 7\n", pf.token()); 20: return; 21: break; 22: 23: case 1: 24: pf.defer(9); 25: printf("2nd-time: Token %zu is deferred by 9\n", pf.token()); 26: return; 27: break; 28: 29: case 2: 30: printf("3rd-time: Tokens 2, 7 and 9 resolved dependencies for token %zu\n", pf.token()); 31: break; 32: } 33: } 34: // token 2 is deferred 35: else if (pf.token() == 2) { 36: switch(pf.num_deferrals()) { 37: case 0: 38: pf.defer(8); 39: printf("1st-time: Token %zu is deferred by 8\n", pf.token()); 40: break; 41: case 1: 42: printf("2nd-time: Token 8 resolved dependencies for token %zu\n", pf.token()); 43: break; 44: } 45: } 46: else { 47: printf("stage 1: Non-deferred token %zu\n", pf.token()); 48: } 49: }; 50: 51: // second_pipe_callable is same as lines 55-57 in the above code snippet 52: auto second_pipe_callable = [](tf::Pipeflow& pf){ 53: printf("stage 2: input token %zu (deferrals=%zu)\n", pf.token(), pf.num_deferrals()); 54: }; 55: 56: // third_pipe_callable is same as lines 59-61 in the above code snippet 57: auto third_pipe_callable = [](tf::Pipeflow& pf){ 58: printf("stage 3: input token %zu\n", pf.token()); 59: }; 60: 61: pipes.emplace_back(tf::PipeType::SERIAL, first_pipe_callable); 62: pipes.emplace_back(tf::PipeType::SERIAL, second_pipe_callable); 63: 64: // create a pipeline of four parallel lines based on the given vector of pipes 65: tf::ScalablePipeline pl(4, pipes.begin(), pipes.end()); 66: 67: tf::Task task = taskflow.composed_of(pl); 68: 69: // run the pipeline 70: executor.run(taskflow).wait(); 71: 72: // reset the pipeline to a new range of three pipes and starts from 73: // the initial state (i.e., token counts from zero) 74: pipes.emplace_back(tf::PipeType::SERIAL, third_pipe_callable); 75: pl.reset(pipes.begin(), pipes.end()); 76: 77: executor.run(taskflow).wait();
Debrief:
- Lines 2 defines the vector of tf::
Pipe type - Lines 6-49 define the first pipe callable
- Lines 52-54 define the second pipe callable
- Lines 57-59 define the third pipe callable
- Lines 61-62 define the vector of two pipe callables
- Line 65 defines the scalable pipeline
- Line 67 defines the pipeline taskflow graph using composition
- Line 70 executes the taskflow for the first run
- Line 74 inserts the third pipe callable in the vector
- Line 75 resets the pipes to three pipe callables
- Line 77 executes the taskflow for the second run
Learn More about Taskflow Pipeline
Visit the following pages to learn more about pipeline: